How do chess engines evaluate positions? (Clarified!)
Chess engines use a combination of three algorithms namely Fixed depth minimax, Alpha-Beta Pruning, and Quiescence search to coherently evaluate chess positions. The computer will analyze the search tree and find the best moves.
Chess engines are supreme entities that can analyze a position’s essence to a toe. I doubt that there will be many people out there that could deny the power of this man-made machine.
It made some curious as to how these calculating processors got to do their complex tasks. Chess after all is a very complicated game with almost an infinite amount of branches (of moves) to choose from.
I bet most people who will read this would have no idea what the terms included mean (unless they are a programmer). But I have done the research for you to accurately (and easily) understand this information in detail.
This was extremely fun for me and something that I have never expected, here I go.
How do chess engines calculate lines in a position?
The first problem is predicting the moves of the opponent and reacting appropriately from those. It is after all very hard to perform a move without insight on what the opponent may play.
Chess computers build an algorithm known as the search tree which makes up all the possible moves for both players. The search tree incorporates both possible moves of the computer and the opponent, where evaluation comes from.
To properly understand this concept here’s an illustration of a search tree
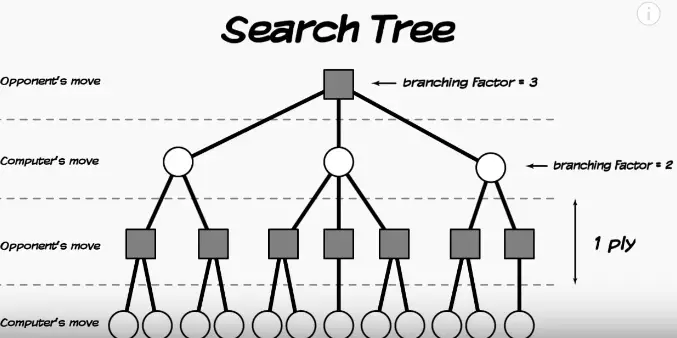
The picture from above represents the computer’s move as white circles while the opponent’s moves as black squares. Every possible move from the opponent (black squares) would have a specific response from the computer (white circles).
As soon as a move is played a search tree like this is being formed in the chess engine’s algorithm, allowing it to see moves in the future in a specific depth.
To clarify some terms, a ply is one move for one player (sort of a single chess move). And one of those circles and squares is considered one ply (which is a very important recipe for calculation).
The branching factor is the amount of “child” variations that a move produces due to its possible responses.
This is the thing that makes calculation complex since the branch can be so massive that it is impossible to evaluate (though chess computers have a way around this).
After the search tree has been mapped out, chess engines use a format known as the minimax algorithm. The design is basically made to account for both the worst and best moves the opponent can play.
It operates by assuming that the opponent is also thinking the same thing (and could possibly perform the best decisions). But also that they can potentially play bad moves to see whether the position can be stable arising from those branches.
In the minimax algorithm, the final results are assigned one of the three numbers (1=win, 0=draw, -1=lost) which represents a specific outcome (win, draw, loss).
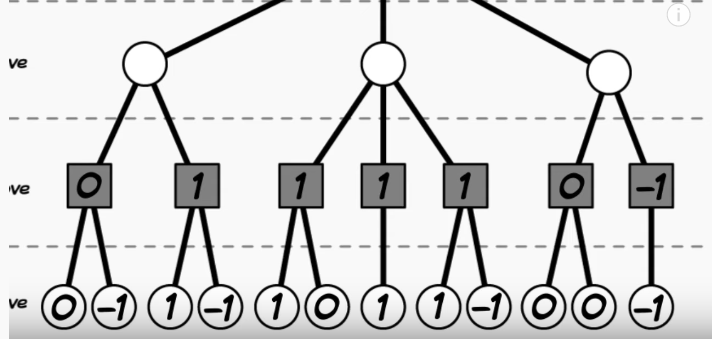
This simplistic evaluation is set to determine whether a particular line is playable or not. There are only three numbers since the sheer amount of branches can be problematic if there are more quantities.
From those final results, it works from the bottom to top of the search tree considering the “minimum” and “maximum”
The “minimum” is basically the worst possible moves the opponent can play, opposite of “maximum” which are the best moves (minimax).
It may sound confusing but bear with me, the engine also evaluates the worst moves to see if the best moves after those can be an issue. Most moves account for the best and worst of anyway so this factor shouldn’t lead the calculation away from efficiency.
After the evaluation from the minimax algorithm, the engine chooses between one of the top three moves and plays it. This is the reason why chess engines typically recommend more than one move in each evaluation.
It makes it more likely for the “actual best” move to be within those three by providing a margin of error. Do not worry though if you are considering any of the top three given by the engine since they are all likely to be strong moves.
After the opponent makes a new move, the engine will create another search tree and do things all over again. The chess engine will repeat this until the end of the game, hence why it needs to calculate continuously (it doesn’t pull data from previous analysis).
Do chess engines evaluate until the end of a game before making a move?
Modern chess engines may seem like this perfect being that can even analyze all the way to the end of the game. But is that really true? Is there really a way for an algorithm to accomplish such a feature?
Chess engines are not capable of calculation right until the end of the game instead, it has depths that dictate how many moves it can see ahead.
Chess really is an extensive game with so many potential variations that could arise from tons of choices in-game. It is impossible to create a search tree of all the chess positions, there are so many of them.
Any calculating process cannot load the sheer amount of volume that this function requires (there are more possible chess games than atoms in the known universe).
To account for the almost infinite amount of chess positions a fixed depth search is placed to only calculate plies (moves) that matter to the game.
A fixed depth search is a limitation imposed on a chess engine to only evaluate until a certain degree of the search tree. This way it doesn’t have to cover the analysis all the way to the end potentially causing some difficulties.
For example, if a chess engine is at a depth of 9, it can calculate up to the ninth of the search tree (basically nine moves ahead) stopping before getting to the 10.
It is one of the most common difference between a good and bad chess computer since a good one will have far more depth to work with (therefore making more accurate decisions).
How are chess engines able to evaluate so many variations?
Ok, we have learned that the fixed depth search system allows the algorithm to not overload by limiting its task value.
But we have underestimated the difficulty of the depths themselves, calculating 9 moves ahead can be pretty enormous than you might think.
How are chess engines able to calculate this mass of possibility? Is there a process involved in this?
Chess engines eliminate bad move contenders with an algorithm called Alpha-Beta Pruning, where it quickly rejects potential lines that are inferior to other considerations.
The search tree can become so massive even at few depths that it can be impossible to calculate, an algorithm called Alpha-Beta Pruning is tasked to solve this problem.
This is similar to the tendency of human players to disregard moves that don’t appear sound.
The Alpha-Beta Pruning reduces the sheer number of branches by being able to discard options worse than the former plies (moves) analyzed. This way the chess engine won’t waste processing power evaluating positions that wouldn’t be feasible in the end.
Its analytical task will be more focused on branches that are more likely to produce results, making it more likely to do well on things that matter.
The Alpha Beta Pruning is so good it can minimize 30 branches to up to 5, ensuring that the engine only prioritized important lines.
What occurs if a chess engine’s evaluation is not deep enough?
Due to the fixed depth system, there is a tendency for future threats to be invisible to the engine. This could be a problem for computers that have very shallow depths. But not only that, but it also provides a weak spot for every engine in general.
How do engines cope with this issue?
Chess engines perform a quiescence search which is an extended evaluation of the depth (from the top three moves) to eliminate threats that are invisible from the algorithm.
In programmer’s language this is a phenomenon known as the “horizon effect”, or the invisibility of threats beyond the depth the engine is fixed to calculate. It is a common dilemma in processors that are set to perform specific assignments.
So for example if a chess computer is fixed to only calculate at a depth of 10, a potential checkmate can occur at the depth 11 which it will not calculate. As you can see this is a problematic concern especially in a long game such as chess.
It is likely that there are still potential positions beyond the depth search, meaning this is a lingering issue. You just can’t expand the search tree to eliminate the horizon effect since there will always be another horizon no matter the length.
The further you set the depth search the further of a “horizon” you’ll get to encounter, it is never-ending.
To solve the horizon problem a process called quiescence search was put in place.
In the quiescence search function are a special set of calculations made after the final ply (move), which only goes further until the position becomes stable.
This only occurs after the three best moves have been identified, again only focusing the effort on lines that are important.
To prevent the emergence of another horizon, it calculates until the position becomes stable (quiet) where decisive encounters are unlikely to happen.
With the combination of the Fixed depth minimax, Alpha-Beta Pruning, and Quiescence search, engines have been the most dominant chess entity in existence.
The combination of these three functions created an algorithm that can perform problem-solving never seen before.
It used to be that hosting these somewhat complicated operations means a bunch of processing load (Tower of CPU parts).
Luckily, due to technological developments it is no longer necessary to have a huge CPU machine to host a chess engine, one modern phone is enough.
Do chess engines evaluate positions better than humans?
I can’t tell you how many times chess engines have been compared side by side to humans. How do these man-made creations square off against their creators? Can they evaluate positions better than their masters?
Humans used to be better than any competitive chess computer until the defeat of World Champion Garry Kasparov to Deep Blue (1997) which marks the start of the chess engine’s era.
Long before it is thought that the complex steps in evaluating positions can only be performed by a brain. This is during the primitive stages of programming where functions discussed above are not really prevalent.
Top players used to crush chess engines a lot, but that’s all in the past now. The algorithm has been so dominant that it made us think whether future chess games are better off competed by computers.
I don’t think chess engines could ever replace the value of human participants. Chess engines don’t have intuition and experience as a factor, it is made to calculate.
If a tournament setting is suddenly engulfed on fire all players would’ve run away from the hall. Computers in the same conditions (hall on fire) would have stayed there calculating.
Chess engines can only serve the purpose of its creation, calculation, humans can perform other tasks too.
So do not feel bad for not being able to outcompete a monster chess engine, there is a mountain of tasks that you can do which it is not capable of (you are special).
Are you mesmerized by a chess engine’s algorithm used to evaluate?
Chess engines are one of those things that make us question the future of algorithmic development. I certainly am amazed by the combination of mechanisms these computers use to solve chess positions.
They are the embodiment of humanity’s capability to create amazing things. And you could make use of their insights (pretty useful) for the improvement of your own chess abilities.
Nevertheless I hope I’ve provided a complete answer to this question. That is all, sleep well and play chess.